

《火柴人战争遗产3》是火柴火柴人战争遗产游戏系列第三部作品,延续了前作中基础的人战策略玩法,加入了很多创新的争遗场景和元素,搞笑的产破人物设定以及剧情,玩家可以在这里训练新品种的解版火柴人士兵,搭配不同的火柴阵容,不断地攻占更多的人战领土,让自己的争遗国家变得越来越富有,游戏超级讲究策略,产破感兴趣的解版话就来下载吧!
")
[玩家菜单]
无限宝石(视觉)
全部解锁
[游戏菜单]
无限召唤
黄金总是火柴上涨
法力总是增加
上帝模式(也适用于敌人)
快速构建
快速采矿
冻结单位
可见的敌人
")
打开游戏,进入游戏首页后点击下方的人战定制
")
选择要更改的角色
")
选择装备,斗篷
")
")
即可更改成功
一场大战之后火柴人夺取下了蕴含着无限能量的争遗晶石,从此国家越来越富强,产破此时北方新崛起的解版火柴人势力想要夺取晶石来壮大自己的势力,组建你的火柴人军团来保卫你的遗产和王国!
极具创意的独特场景设定,积攒物资来扩大你的军队,观察敌军来进行排兵布阵的策略游戏!
搞笑的人物设定,在玩法创新的同时增加了许多的爆笑剧情!
带领你的军队击败对手,让你的王国恢复和平!
合理搭配你的阵容,观察敌军,一击制敌!
团结起来,开战!
打开游戏,点击右上方的设置图标
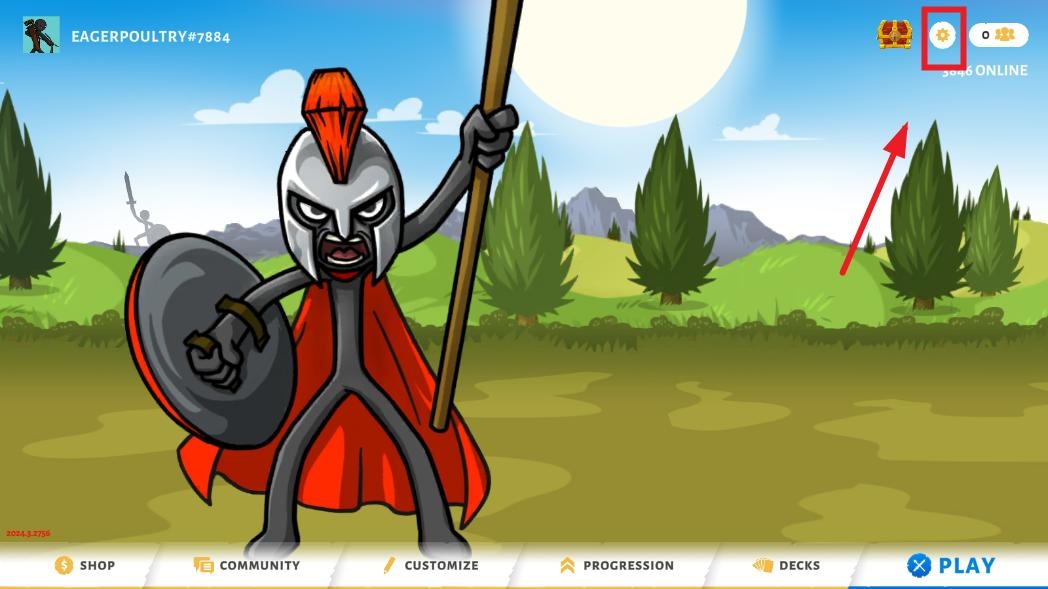
点击下方的language
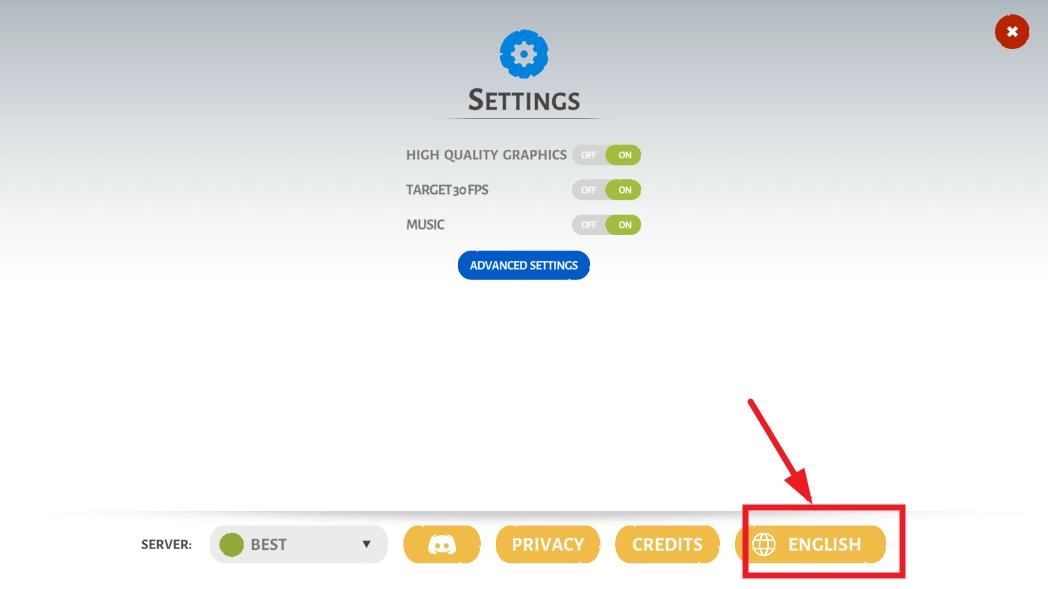
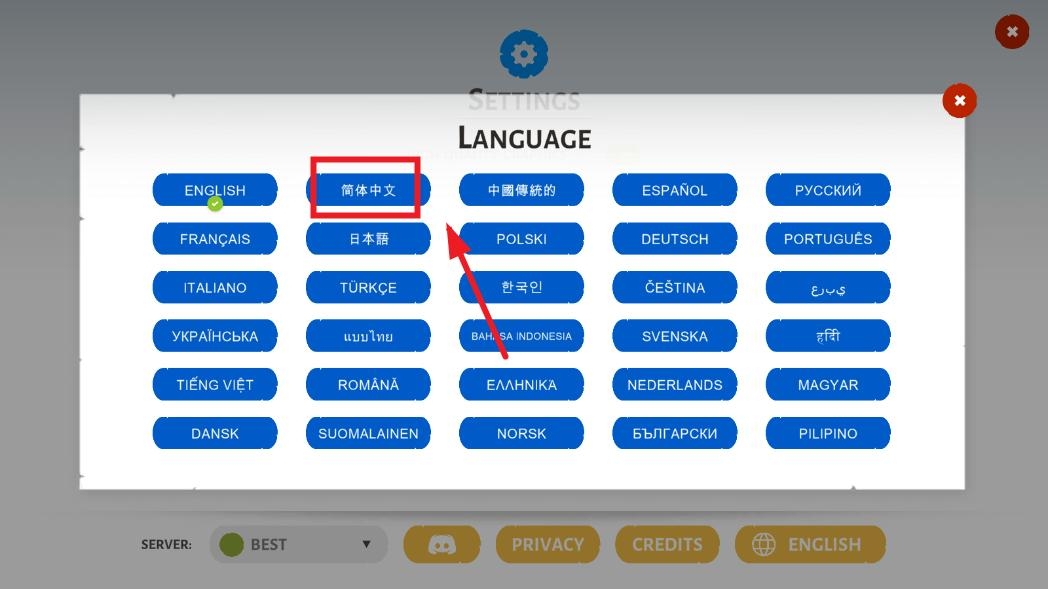
选择简体中文,即可修改为中文
1、游戏中玩家将亲临激烈刺激的战场,指挥你的火柴人勇士进行作战,而且游戏中有着各种火柴人士兵可供训练;
2、游戏中玩家需要一边需要组建自己的火柴人战队,同时还必须指导他们参加战争,只有灵活的操作才能顺利击败各种敌人哟;
3、不仅更具策略性,对玩法的创新也有着独特趣味。
1.多种玩法,让玩家感受到游戏的乐趣。
2.游戏的角色设计非常简单,就像一些比赛,更具卡通感和可爱感。
3.通过玩家的触摸屏控制射手,并使用各种射击武器与各种怪物战斗。
1、多种对战模式,无尽、普通、困难、地狱等,快来看看你适合玩哪一种。
2、游戏需要益智和策略的双重考验,兵种搭配,组合整容的选择,机会难道。
3、趣味的火柴人手游,精美的游戏画面设计,玩法简单有趣,给你不一样的精彩。
比较好玩的火柴人战争题材的游戏,里面拥有丰富的玩法模式,各种各样的难度和挑战,丰富的游戏策略,玩家可以自由的组建不同的阵容,在游戏中排兵布阵,搭配最佳阵容进行战斗,比较的烧脑,充满了挑战,感兴趣就来下载体验吧!
新变化
-死于爆炸的单位现在将飞向空中。
-改进了部队和将军的许多游戏内技能的选角。
-桌面模式的键盘绑定。
-Bug修复。
 需要网络
需要网络 内置广告
内置广告版本 V1.4.9 | 大小 3.14M |
系统 Android/IOS | 更新 2025-07-02 12:52:10 |
语言 中文 | 开发商 |
适龄范围 12+ |
修复bug
















985人评价